




It has been widely acknowledged that coding is an art, and like every artisan who crafts wonderful art and is proud of them, we as developers are also really proud of the code we write. In order to achieve the best results, artists constantly keep searching for ways and tools to improve their craft. Similarly, we as developers keep levelling up our skills and remain curious to know the answer to the single most important question - “How to write good code”. 🤯
Frederick P. Brooks in his book “ The Mythical Man Month: Essays on Software Engineering ” wrote :
“The programmer, like the poet, works only slightly removed from pure thought-stuff. He builds his castles in the air, from air, creating by exertion of the imagination. Few media of creation are so flexible, so easy to polish and rework, so readily capable of realizing grand conceptual structures.
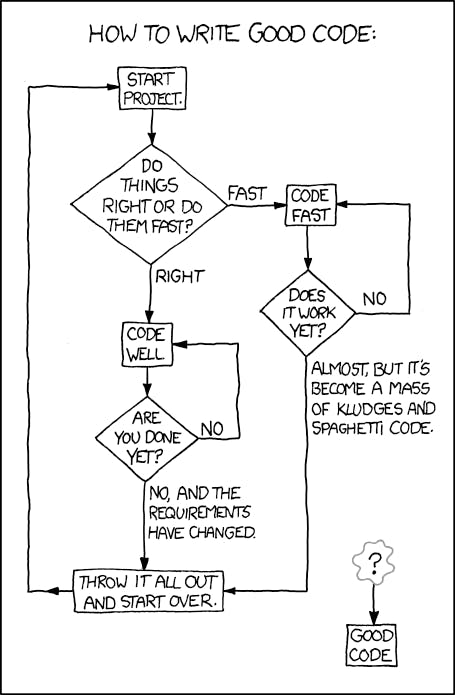
Image source: https://xkcd.com/844/
This post tries to explore answers to the big question mark in the comic above. The simplest way to write good code is to abstain from including anti-patterns in the code we write.😇
What are anti-patterns? 🤔
Anti-patterns occur when code is written without taking future considerations into account. Anti-patterns might initially appear to be an appropriate solution to the problem, but, in reality, as the codebase scales, these come out to be obscure and add ‘technical debt’ to our codebase.
A simple example of an anti-pattern is to write an API without considering how the consumers of the API might use it, as explained in example 1 below. Being aware of anti-patterns and consciously avoid using them while programming is surely a major step towards a more readable and maintainable codebase. In this post, let’s take a look at a few commonly seen anti-patterns in Go.
1. Returning value of unexported type from an exported function
In Go, to export any field or variable we need to make sure that its name starts with an uppercase letter. The motivation behind exporting them is to make them visible to other packages. For example, if we want to use the Pi function from math package, we should address it as math.Pi . Using math.pi won’t work and will error out.
Names (struct fields, functions, variables) that start with a lowercase letter are unexported, and are only visible inside the package they are defined in.
An exported function or method returning a value of an unexported type may be frustrating to use since callers of that function from other packages will have to define a type again to use it.
// Bad practice
type unexportedType string
func ExportedFunc() unexportedType {
return unexportedType("some string")
}
// Recommended
type ExportedType string
func ExportedFunc() ExportedType {
return ExportedType("some string")
}
2. Unnecessary use of blank identifier
In various cases, assigning value to a blank identifier is not needed and is unnecessary. In case of using the blank identifier in for loop, the Go specification mentions :
If the last iteration variable is the blank identifier, the range clause is equivalent to the same clause without that identifier.
// Bad practice
for _ = range sequence
{
run()
}
x, _ := someMap[key]
_ = <-ch
// Recommended
for range something
{
run()
}
x := someMap[key]
<-ch
3. Using loop/multiple appends to concatenate two slices
When appending multiple slices into one, there is no need to iterate over the slice and append each element one by one. Rather, it is much better and efficient to do that in a single append statement.
As an example, the below snippet does concatenation by appending elements one by one through iterating over sliceTwo.
for _, v := range sliceTwo {
sliceOne = append(sliceOne, v)
}
But, since we know that append is a variadic function and thus, it can be invoked with zero or more arguments. Therefore, the above example can be re-written in a much simpler way by using only one append function call like this:
sliceOne = append(sliceOne, sliceTwo…)
4. Redundant arguments in make calls
The make function is a special built-in function used to allocate and initialize an object of type map, slice, or chan. For initializing a slice using make, we have to supply the type of slice, the length of the slice, and the capacity of the slice as arguments. In the case of initializing a map using make, we need to pass the size of the map as an argument.
make, however, already has default values for those arguments:
- For channels, the buffer capacity defaults to zero (unbuffered).
- For maps, the size allocated defaults to a small starting size.
- For slices, the capacity defaults to the length if capacity is omitted.
Therefore,
ch = make(chan int, 0)
sl = make([]int, 1, 1)
can be rewritten as:
ch = make(chan int)
sl = make([]int, 1)
However, using named constants with channels is not considered as an anti-pattern, for the purposes of debugging, or accommodating math, or platform-specific code.
const c = 0
ch = make(chan int, c) // Not an anti-pattern
5. Useless return in functions
It is not considered good practice to put a return statement as the final statement in functions that do not have a value to return.
// Useless return, not recommended
func alwaysPrintFoofoo() {
fmt.Println("foofoo")
return
}
// Recommended
func alwaysPrintFoo() {
fmt.Println("foofoo")
}
Named returns should not be confused with useless returns, however. The return statement below really returns a value.
func printAndReturnFoofoo() (foofoo string)
{
foofoo = "foofoo"
fmt.Println(foofoo)
return
}
6. Useless break statements in switch
In Go, switch statements do not have automatic fallthrough. In programming languages like C, the execution falls into the next case if the previous case lacks the break statement. But, it is commonly found that fallthrough in switch-case is used very rarely and mostly causes bugs. Thus, many modern programming languages, including Go, changed this logic to never fallthrough the cases by default.
Therefore, it is not required to have a break statement as the final statement in a case block of switch statements. Both the examples below act the same.
Bad pattern:
switch s {
case 1:
fmt.Println("case one")
break
case 2:
fmt.Println("case two")
}
Good pattern:
switch s {
case 1:
fmt.Println("case one")
case 2:
fmt.Println("case two")
}
However, for implementing fallthrough in switch statements in Go, we can use the fallthrough statement. As an example, the code snippet given below will print 23.
switch 2 {
case 1:
fmt.Print("1")
fallthrough
case 2:
fmt.Print("2")
fallthrough
case 3:
fmt.Print("3")
}
7. Not using helper functions for common tasks
Certain functions, for a particular set of arguments, have shorthands that can be used instead to improve efficiency and better understanding/readability.
For example, in Go, to wait for multiple goroutines to finish, we can use a sync.WaitGroup. Instead of incrementing a sync.WaitGroup counter by 1 and then adding -1 to it in order to bring the value of the counter to 0 and in order to signify that all the goroutines have been executed :
wg.Add(1)
// ...some code
wg.Add(-1)
It is easier and more understandable to use wg.Done() helper function which itself notifies the sync.WaitGroup about the completion of all goroutines without our need to manually bring the counter to 0.
wg.Add(1)
// ...some code
wg.Done()
8. Redundant nil checks on slices
The length of a nil slice evaluates to zero. Hence, there is no need to check whether a slice is nil or not, before calculating its length.
For example, the nil check below is not necessary.
if x != nil && len(x) != 0 {
// do something
}
The above code could omit the nil check as shown below:
if len(x) != 0 {
// do something
}
9. Too complex function literals
Function literals that only call a single function can be removed without making any other changes to the value of the inner function, as they are redundant. Instead, the inner function that is being called inside the outer function should be called.
For example:
fn := func(x int, y int) int {
return add(x, y)
}
Can be simplified as:
fn := add
10. Using select statement with a single case
The select statement lets a goroutine wait on multiple communication operations. But, if there is only a single operation/case, we don’t actually require select statement for that. A simple send or receive operation will help in that case. If we intend to handle the case to try a send or receive without blocking, it is recommended to add a default case to make the select statement non-blocking.
// Bad pattern
select {
case x := <-ch:
fmt.Println(x)
}
// Recommended
x := <-ch
fmt.Println(x)
Using default:
select {
case x := <-ch:
fmt.Println(x)
default:
fmt.Println("default")
}
11. context.Context should be the first param of the function
The context.Context should be the first parameter, typically named ctx. ctx should be a (very) common argument for many functions in a Go code, and since it’s logically better to put the common arguments at the first or the last of the arguments list. Why? It helps us to remember to include that argument due to a uniform pattern of its usage. In Go, as the variadic variables may only be the last in the list of arguments, it is hence advised to keep context.Context as the first parameter. Various projects like even Node.js have some conventions like error first callback. Thus, it’s a convention that context.Context should always be the first parameter of a function.
// Bad practice
func badPatternFunc(k favContextKey, ctx context.Context) {
// do something
}
// Recommended
func goodPatternFunc(ctx context.Context, k favContextKey) {
// do something
}
When it comes to working in a team, reviewing other people’s code becomes important. DeepSource is an automated code review tool that manages the end-to-end code scanning process and automatically makes pull requests with fixes whenever new commits are pushed or new pull requests.
Setting up DeepSource for Go is extremely easy. As soon as you have it set up, an initial scan will be performed on your entire codebase, find scope for improvements, fix them, and open pull requests for those changes.
go build
Originally published on DeepSource Blog .